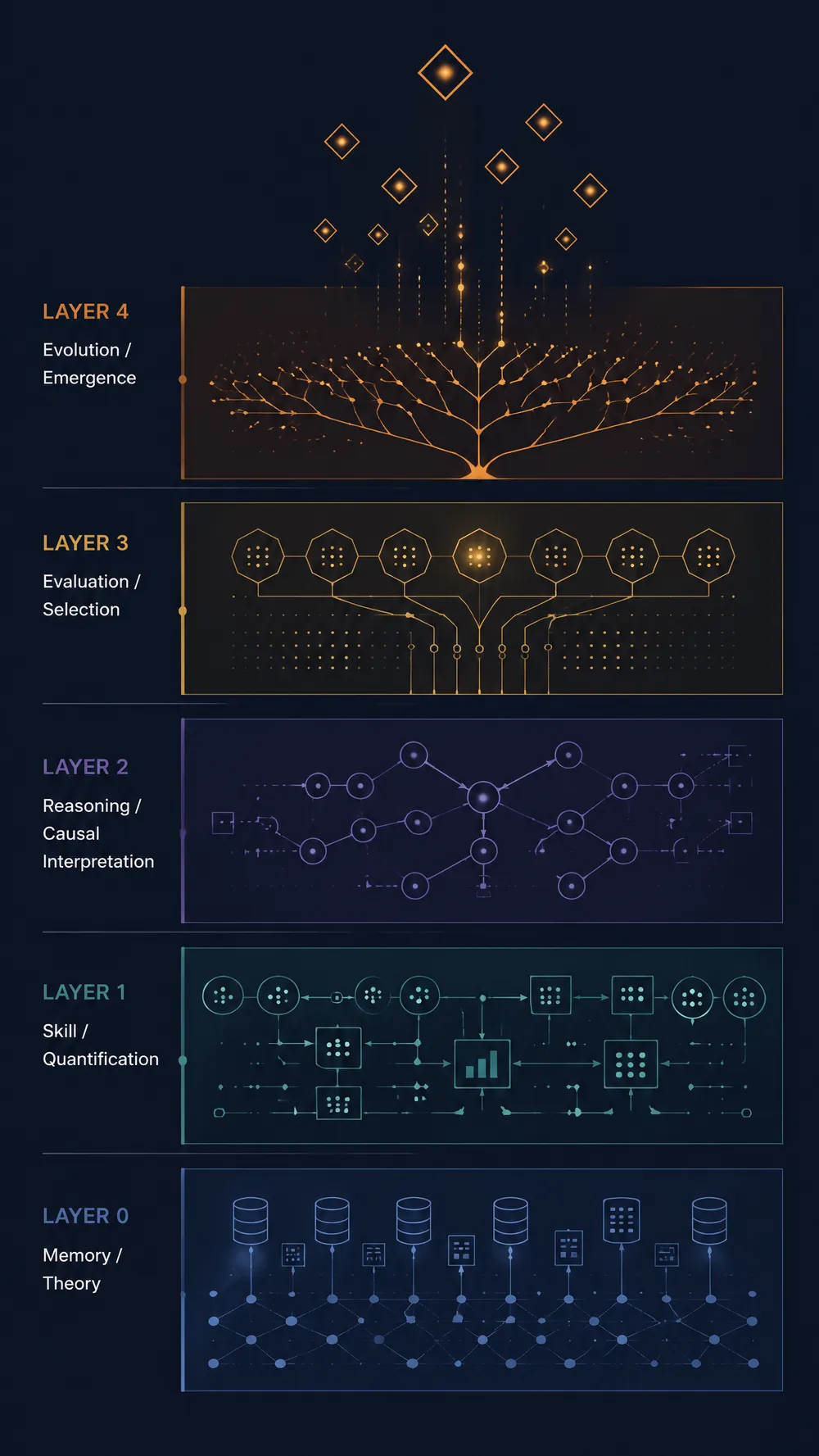
评测框架
EvoSika 采用四层评测架构,从因果涌现到干预效力,全面评估基因集的科学与临床价值。
Module 1 — 因果涌现
评估概念是否比单个基因展现更强的疾病关联。通过因果涌现指数(CE Index)量化整体涌现效应,验证基因集是否真正实现了「1+1>2」的涌现效应。
核心指标:CE Index(因果涌现指数)、AUC(疾病分类精度)
Module 2 — 简约性
评估基因集能否以最少的变量达到同等的疾病分类效果。通过 ElasticNet 正则化(L1+L2)自动选择关键基因,评估简约性得分。
核心指标:Parsimony Score(简约性得分)、非零系数数量
Module 3a — 泛疾病解释力
评估基因集是否对多种疾病具有普适的解释力。通过跨疾病数据集(乳腺癌、肠癌、抑郁症等)验证其泛化能力。
核心指标:Universal Disease Score(泛疾病得分)、跨疾病 AUC 均值
Module 3b — 干预效力
评估基因集是否能响应有效的干预措施。通过真实 GEO 临床试验数据(叶酸、黄酮醇、二甲双胍等)验证干预响应能力。
核心指标:Universal Intervention Score(泛干预得分)、干预前后显著性
进化机制
EvoSika 的进化引擎借鉴梅花鹿角脱落再生的自然智慧,实现理论的持续迭代优化。
适应度超过阈值(≥0.5),新概念直接加入基因集库
与已有 Agent 高度相似(Jaccard≥0.8),融合为新版本
概念内部存在明显子结构,分裂为多个子 Agent
优于已有相似 Agent(Jaccard 0.3-0.8),替换旧版本
适应度不足,概念被淘汰
分布式计算工具包
下载 EvoSika 计算包,在本地运行评测任务,提交结果到排行榜。
支持 Windows / macOS / Linux
计算包包含:评测脚本 + 参考数据集 + SHA-256 基因集指纹
四维评测体系

Layer 1:因果涌现
这个概念是否真的与疾病因果相关?通过因果涌现指数(CE Index)量化宏观涌现效应——Hallmark级特征比单个基因强出最高9.7个数量级。
Layer 2:简约性
用这个基因集表征这个概念,是否以最少变量达到同等预测精度?通过LASSO/ElasticNet评估精简度得分。
Layer 3:泛疾病解释力
这个概念是否对多种疾病具有普适解释力?跨10种年龄相关疾病数据集验证。
Layer 4:可干预效力
这个概念能否区分有效干预和无效干预?通过GEO真实临床试验数据,验证概念在干预前后的显著变化和疗效中介效应。
三步参与
定义你的概念
输入一个生物学概念名称(如"线粒体功能障碍"、"气虚"),提交你认为最能表征该概念的基因集合。系统自动注册为标准化的Hallmark Agent。
AI自动评测
你的Agent进入Hallmarks Engineering Testbed评测队列。离线评测引擎在公开数据集上自动执行四维评测(因果涌现、简约性、泛疾病解释力、可干预效力)。预计12小时内完成。
查看排名与进化
评测完成后,你的Agent出现在公开排行榜上。在每个疾病的榜单、每个评测维度的分榜、以及跨疾病综合总榜中,你可以看到它的精确排名。优胜者保留,缺陷者淘汰,两个优秀概念可自发融合。